90%
Improvement in aligning responses to user personas
1.36s
Reduction in query time via KV caching
100%
Data privacy achieved by hosting local LLM
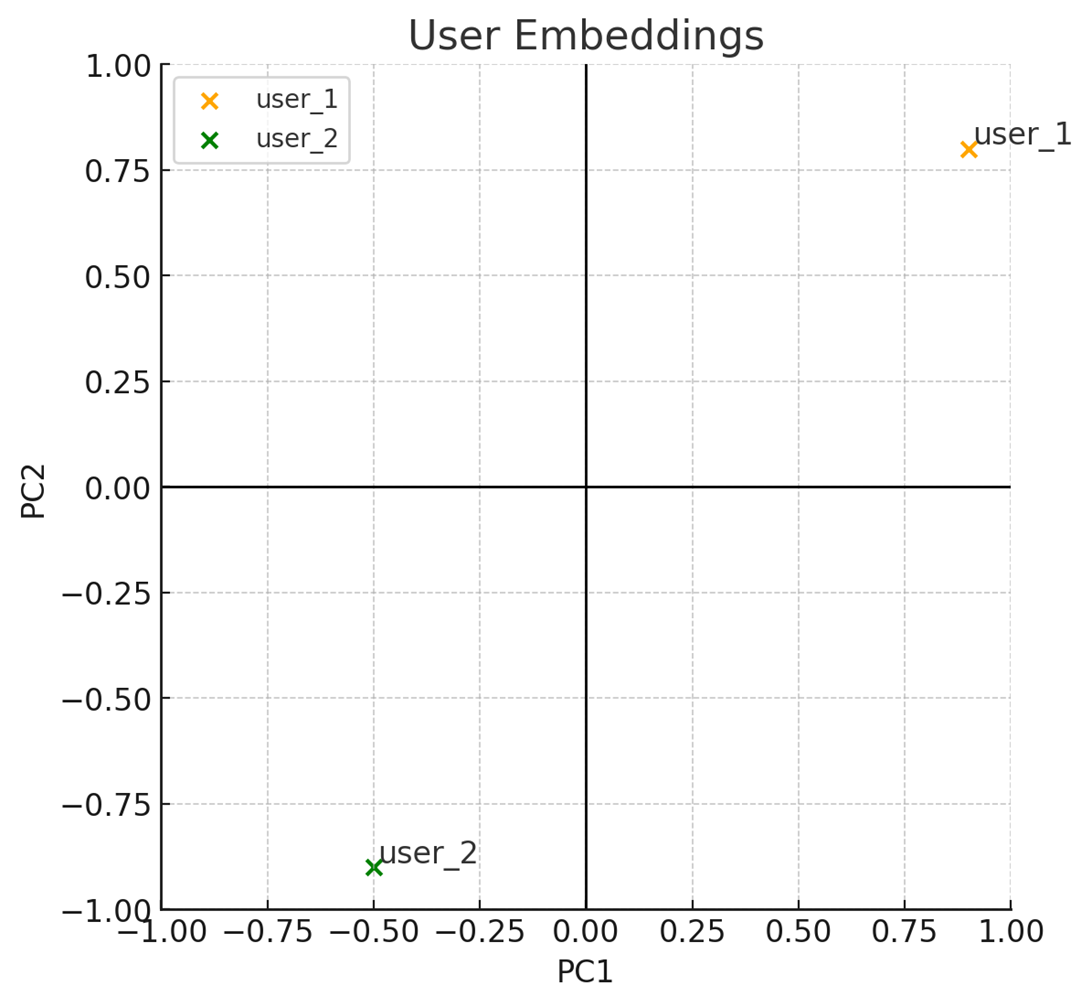
PCA plot showing the learned embeddings for the 'lawyer' (user_1) and 'social media analyst' (user_2). Their separation demonstrates the model successfully captured their distinct preferences.
I enhanced a commercial RAG system to address data privacy risks and enable automatic user personalisation. I developed a local LLM with a custom user-embedding layer that learns individual preferences from star ratings. The final system adapted its response style to different user personas, making a lawyer persona 90% more likely to receive a detailed, formal response.
The Problem
The existing system sent user data to third-party APIs, which was unacceptable for clients with sensitive information. The system also had no memory for user preferences between sessions, causing user frustration.
Technical Solution
System Architecture
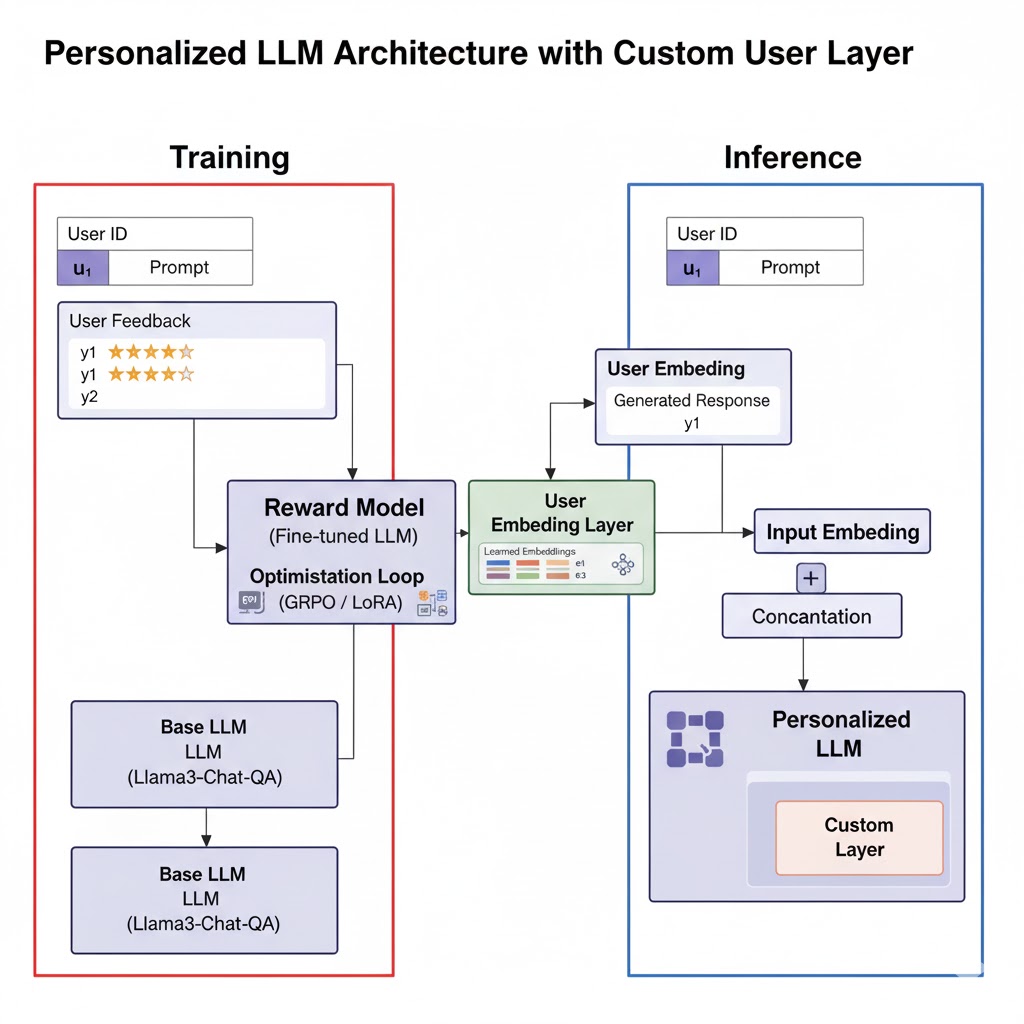
Architecture diagram showing the RAG system, user feedback loop, local LLM, and custom user-embedding layer integration.
Architecture
My solution uses a Representation Learning Approach. I subclassed a LlamaForCausalLLM to introduce a custom user-embedding layer. This layer concatenates a learned user-specific vector with the standard word embeddings. This method allows a single model to serve all users, which avoids the high cost of training a model for each user.
Training and Optimisation
The model was trained using Reinforcement Learning from Human Feedback (RLHF). I used Group Relative Policy Optimization (GRPO) because its low memory footprint was essential for the single Tesla T4 16GB GPU, as it does not require a reference model like PPO. To make training feasible, I used LoRA, 8-bit precision, and Key-Value (KV) caching, which reduced response times by 1.36 seconds per query.
Results
Prompt: What is a projectile?
Lawyer Persona
A projectile is a body that is thrown into the air or projected through space by the action of a propelling force.
Social Media Analyst
A projectile is a body that is shot, flung, or thrown into the air.
Key Learnings
- Hyperparameter Tuning: RLHF training is very sensitive. A high learning rate caused model collapse, where it only outputted the letter "e".
- Hardware Constraints: Optimisation techniques like GRPO, LoRA, and KV caching were not optional. They were essential to successfully train and run the model on a single 16GB GPU.
- Dataset Selection: The choice of dataset is important. The short answers in the SQuAD dataset were not suitable for training a model on style and verbosity. The QuAC dataset was more effective.

